
Khi hiểu về Storage Tiering, doanh nghiệp sẽ dễ quản lý dữ liệu toàn diện hơn, giúp tạo ra chiến lược lão hóa dữ liệu và cho phép tách các bộ dữ liệu lớn chưa sử dụng khỏi ứng dụng, do đó giảm chi phí và đơn giản hóa hoạt động.
Mục lục
Giới thiệu về Storage Tiering
Storage Tiering (phân cấp lưu trữ) là giải pháp ưa thích của doanh nghiệp để giải quyết các vấn đề liên quan đến việc quản lý tốc độ tăng trưởng theo cấp số nhân của dữ liệu, chi phí và hiệu suất ứng dụng. Khái niệm cơ bản của phân cấp lưu trữ là tăng hiệu quả và giảm chi phí bằng cách phân loại dữ liệu dựa trên giá trị của nó và tần suất nó cần được truy cập.
Khi các yêu cầu truy cập đối với các loại dữ liệu đã được xác định, hiệu suất và hiệu quả chi phí sẽ xác định cấp lưu trữ thích hợp nhất dành cho dữ liệu. Sự di chuyển tự động của dữ liệu đến các cấp lưu trữ khác nhau dựa trên giá trị kinh doanh của nó theo truyền thống được gọi là Quản lý vòng đời thông tin (ILM).
Phân cấp lưu trữ hiếm khi được thảo luận giữa các chủ sở hữu ứng dụng cấp 1 và nhóm cơ sở hạ tầng. Mặc dù họ rất cần thiết để điều hành một doanh nghiệp vì họ có xu hướng cấp 1 là lựa chọn duy nhất. Các ứng dụng cấp 1 được thiết kế, cấu hình và triển khai để chạy trên các thiết bị lưu trữ hiệu suất cao, chi phí cao.
Sau khi doanh nghiệp di chuyển sang đám mây hoặc các ứng dụng hiện đại, các yêu cầu lưu trữ đối với dữ liệu còn lại trong mỗi ứng dụng có thể thay đổi. Doanh nghiệp vẫn có thể cần giữ dữ liệu vì lý do tuân thủ hoặc vì một số mục đích kinh doanh khác. Tuy nhiên, nhu cầu truy xuất nhanh sẽ ít hơn. Trong hầu hết các trường hợp này, chi phí và sự tuân thủ thay thế các yêu cầu về tốc độ và hiệu suất cao.
Phân loại dữ liệu
- Mission Critical: Dữ liệu được sử dụng trên một ứng dụng hiệu suất cao, ví dụ: Quản lý giao dịch.
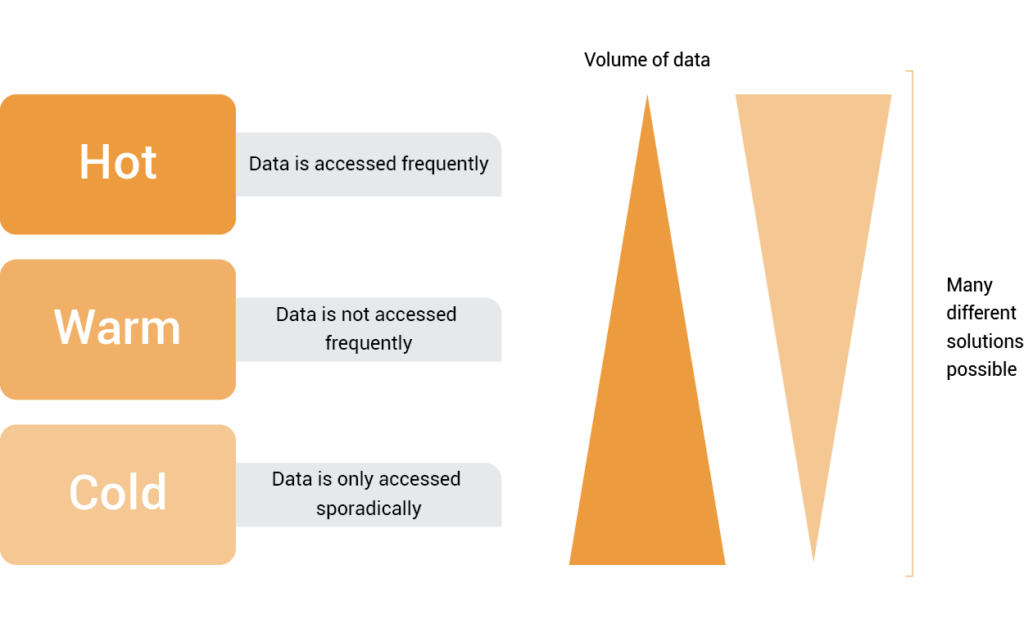
- Hot: Dữ liệu được sử dụng liên tục và nhu cầu cao.
- Warm: Dữ liệu được sử dụng ít thường xuyên hơn, nhưng vẫn phải luôn sẵn sàng truy cập.
- Cold: Dữ liệu phải được giữ lại nhưng có thể không bao giờ được truy cập lại.
Trong số các loại này, Hot, Warm và Cold là các phân loại phổ biến nhất cho các ứng dụng ngừng hoạt động.
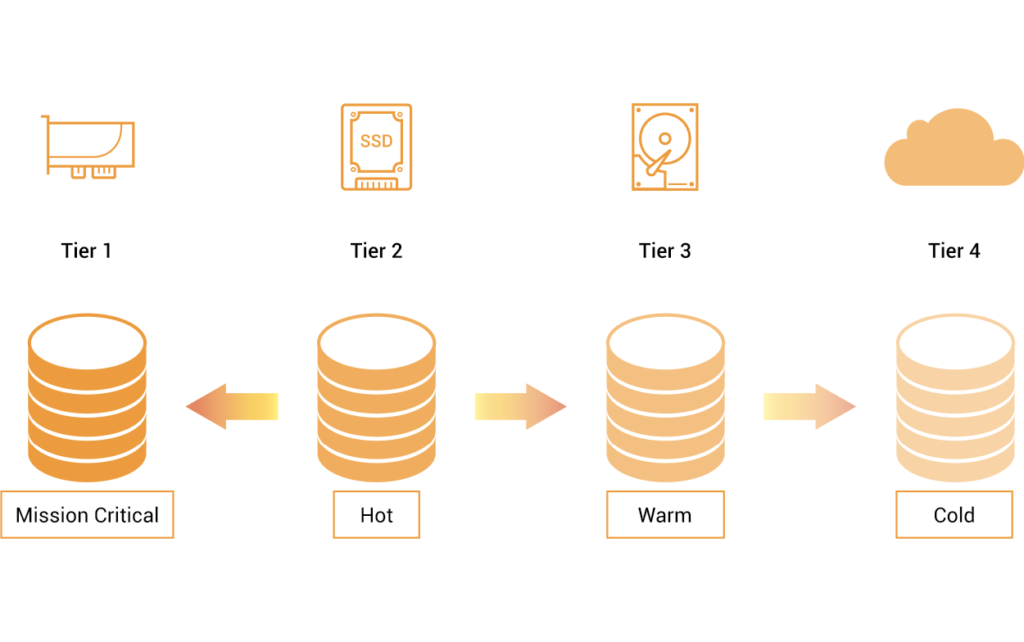
Dữ liệu được lưu trữ trên các phương tiện lưu trữ (các cấp) dựa trên phân loại cơ bản hoặc các giá trị được liệt kê bên dưới:
| Đặc trưng | Tier 0 | Tier 1 | Tier 2 | Tier 3 |
| Loại dữ liệu | Có độ nhạy cao | Hỗ trợ giao dịch | Thường xuyên truy cập | Không được truy cập thường xuyên |
| Truy cập | Nhanh | Sự chậm trễ ngắn | Rất nhanh | Chậm |
| Khả năng thực hiện | Cao | Cao | Vừa phải | Thấp |
| Ví dụ | Dữ liệu giao dịch | Ứng dụng hiệu suất cao | Dữ liệu hệ thống ERP / CRM | Dữ liệu doanh nghiệp tuân thủ |
| Phí tổn | Khá cao | Cao | Vừa phải | Rất thấp |
Tính năng và đặc điểm của các phân loại
| Đặc trưng | Mission Critical | Hot | Warm | Cold |
| Kho | Gần đến thời điểm tính toán | Gần đến thời điểm tính toán | Trên máy chủ từ xa hoặc mạng riêng | Trong các dịch vụ đám mây |
| Tốc độ truy cập | Rất nhanh | Nhanh | Vừa phải | Chậm |
| Định giá | Cao | Cao | Khá cao | Thấp |
| Phương tiện lưu trữ | Tốc biến | SSD | Cổng lưu trữ đám mây hoặc máy chủ tệp / NAS | Băng ổ đĩa chậm hơn |
| Tần suất truy cập | Rất cao | Cao | Khá cao | Thấp |
| Loại dữ liệu được lưu trữ | Các ứng dụng hiệu suất cao | Cần thiết trong kinh doanh hàng ngày | Dữ liệu không được sử dụng trong kinh doanh hàng ngày | Dữ liệu hiếm khi được truy cập |
| Bậc lưu trữ | Tier 0 | Tier 1 | Tier 2 | Tier 3 |
Lợi ích của Storage Tiering
Khi xem xét việc lưu trữ hoặc gỡ bỏ các ứng dụng, một trong những động lực chính là cắt giảm chi phí và đơn giản hóa các hoạt động. Việc thực hiện di chuyển tự động dữ liệu (ILM) sang kho lưu trữ ấm, nóng và lạnh dựa trên quyền truy cập, hiệu suất và giá trị mang lại lợi ích to lớn cho ứng dụng theo những cách sau:
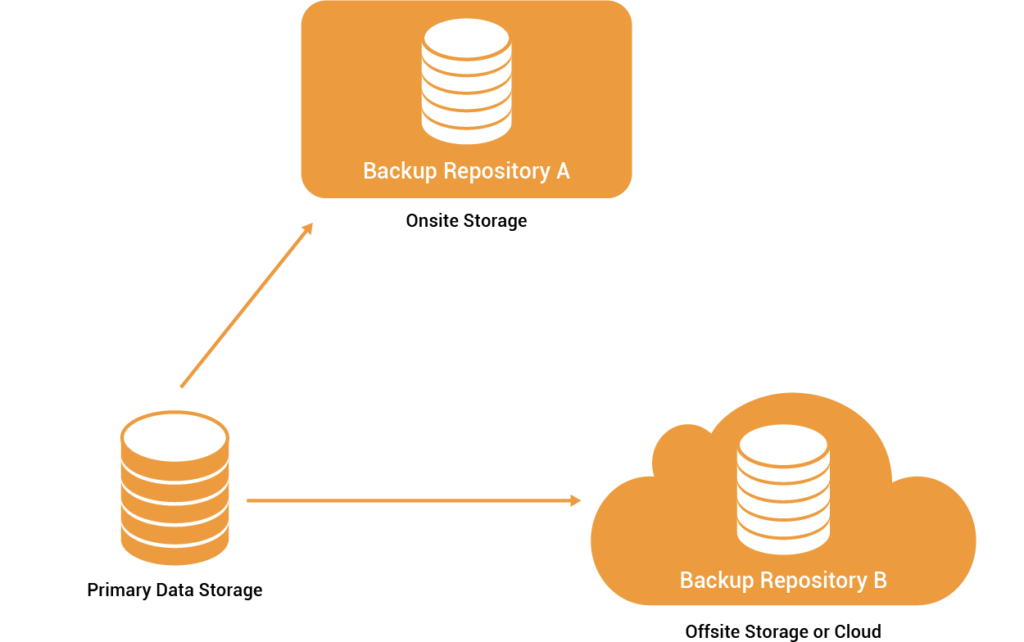
Khôi phục sau thảm họa dễ dàng
Việc di chuyển tự động dữ liệu trên các tầng lưu trữ và lưu trữ một ứng dụng sản xuất có thể giảm đáng kể chi phí và đạt được mục tiêu thời gian khôi phục bằng 0 (RTO) bằng cách giảm lượng dữ liệu mà hệ thống cốt lõi phải khôi phục trong một thảm họa. Ngoài ra, nó còn giảm thời gian sao lưu và giảm lượng dữ liệu trên bộ nhớ cấp 1.
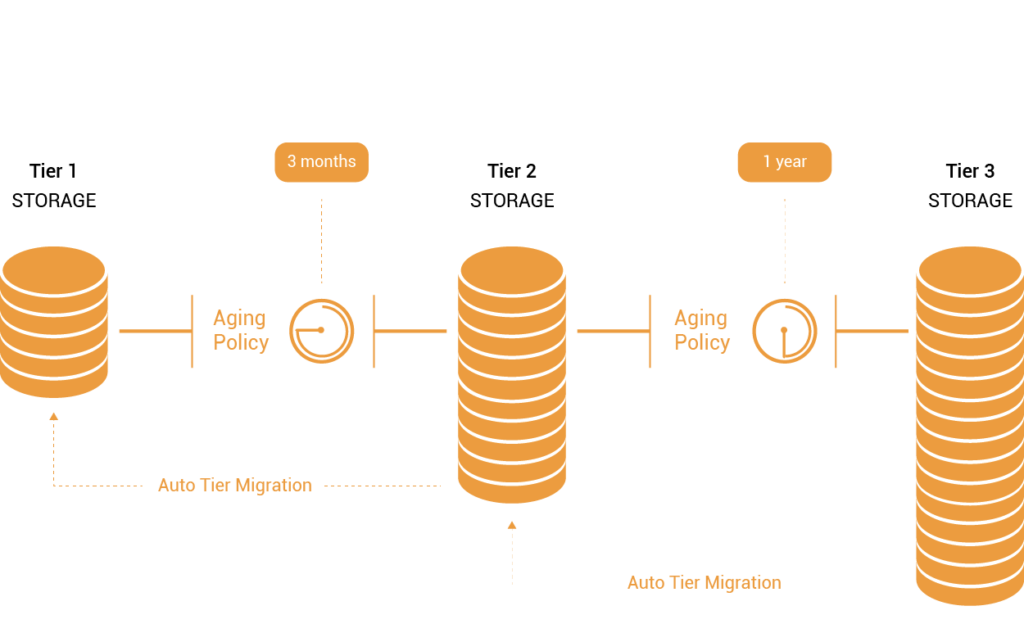
Quản lý dữ liệu được kiểm soát và hiệu quả lưu trữ cao hơn
Vì dữ liệu có thể được phân loại, phân loại và di chuyển đến các cấp khác nhau một cách có hệ thống, nên việc quản lý và kiểm soát trở nên dễ dàng hơn trên quy mô lớn. Ngoài ra, các hệ thống lưu trữ theo tầng giúp giảm bớt nhu cầu và căng thẳng đối với các hệ thống giao dịch bằng cách di chuyển dữ liệu không yêu cầu hiệu suất cao như vậy sang các tầng lưu trữ thấp hơn hoặc ra khỏi ứng dụng hoàn toàn.
Giảm chi phí lưu trữ và sao lưu dữ liệu
Các kiến trúc sư doanh nghiệp sẽ đồng ý rằng phân cấp lưu trữ cho dữ liệu cắt giảm hơn 60% chi phí vì nó lưu trữ dữ liệu lạnh xuống các phương tiện lưu trữ thấp hơn. Quá trình này giúp loại bỏ việc trả tiền cho việc lưu trữ hiệu suất cao không cần thiết cho dữ liệu có giá trị thấp và ít sử dụng. Giảm dung lượng lưu trữ cấp 1 cải thiện quy trình sao lưu dữ liệu và rút ngắn thời gian hoàn thành.
Ngoài những lợi ích cốt lõi này, khả năng tự động hóa phân cấp lưu trữ (ILM) trên các ứng dụng và tập dữ liệu cung cấp tính linh hoạt để sử dụng các hệ thống lưu trữ khác nhau, giảm sự phụ thuộc của lưu trữ tại chỗ và cho phép linh hoạt trong việc di chuyển dữ liệu từ nguồn sang đích dựa trên giá trị kinh doanh và yêu cầu sử dụng.
Kết luận
Khi chuyển đổi hoạt động kinh doanh, hãy kết hợp chiến lược lão hóa dữ liệu cho phép doanh nghiệp phân loại dữ liệu của mình để mang lại sự linh hoạt hơn trong việc quản lý chuyển động và vòng đời dựa trên giá trị, sự tuân thủ và nhu cầu truy cập. Mục tiêu là đạt được sự cân bằng phù hợp giữa hiệu suất, hạn chế chi phí và tuân thủ. Storage Tiering lại tất cả những lợi ích này ở một nơi khi xây dựng chiến lược di chuyển, lưu trữ và ngừng hoạt động dữ liệu.
Để tìm hiểu thêm về dịch vụ FStorage, vui lòng liên hệ đến :
Hotline: Ms.Nhi 0359406812
Fanpage: https://www.facebook.com/fstorage
Email: support@fstorage.vn










